MapReduce is one of the core components of the Hadoop framework and plays an important role in processing huge amounts of structured and unstructured data. The issues associated with traditional ways of parallel and distributed processing have laid roots for the development of the MapReduce framework. In this blog we are going to cover the below topics:
1. What is MapReduce?
2. Different stages available in MapReduce
3. MapReduce architecture & its working style
4. Core components of Hadoop architecture
5. Role of Job Tracker and Task Tracker in MapReduce.
What is MapReduce?
MapReduce is a programming model that simplifies the task of data processing by allowing users to perform parallel and distributed processing on huge volumes of data. As the name depicts it consists of two important tasks which are Map and Reduce. The Reducer task begins once the mapper task is over. The Map task job is to read and process a certain amount of data and produce key-value pairs. The output of Map job (key values) becomes the input for the Reducer task. The Reducer task collects and aggregates the key-value pairs and gives the final output. Hadoop framework is highly flexible and supports the MapReduce programs written in multiple languages which includes Python, Java, Ruby, and C++. The Parallel nature of Mapreduce framework streamlines the procedure to perform analysis on large-scale data analysis by using multiple machines in a cluster.
Stages in MapReduce
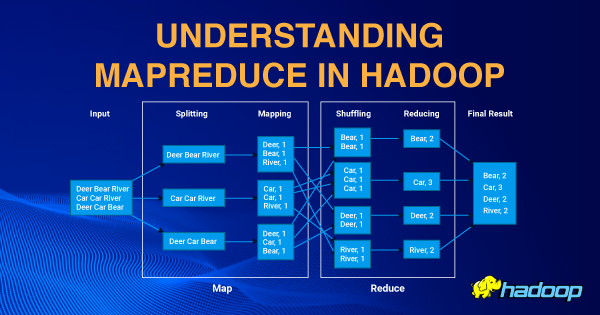
MapReduce performs two functions namely Map and Reduce. In order to accomplish these tasks, it goes through four stages which are splitting, mapping, shuffling, and reducing.

Let us understand each stage in detail:
a) Input Splits: An input to the MapReduce is divided into smaller units called input Splits. An input Split is a part of the input and consumed by a single Map.
b) Mapping: Mapping is the first phase in the MapReduce algorithm. At this stage data in each split is transferred to a mapping function to produce output values. In the above diagram, the Map function segregates each word from input splits.
c)Shuffling: The Shuffling stage takes the output from the map Stage and combines the relevant records. In the above diagram, you can clearly see that all the related items are grouped together with their respective frequencies.
d) Reducing: This is the final stage in the MapReduce algorithm. At the Reduce stage, it takes the output from the Shuffle stage and combines the values in order to produce the final output value. In the above diagram, the Reducer task gives the number of a specific item and produces the final result.
Check out our Big Data Hadoop & Spark training by TrainingHub.io
MapReduce Architecture

The Client component in MapReduce will submit a job of a specific size to the Hadoop MapReduce Master. Then the MapReduce Master divides the job into small equivalent job-parts. All these job-parts are made available for Map and Reduce Task. The Map and Reduce task contains a program written for solving specific problems or to get the desired output. The Developer writes logical programming to meet the business requirement. The input data is consumed by Map task and the Map task produces key-value pairs as a final output. The key value-pairs become the input for the Reducer and final output will be stored on the Hadoop Distributed File System. MapReduce Architecture designed in a way to process a number of Map and Reduce tasks based on the requirement. The Map and Reduce algorithm is designed in a very optimized way which brings down space and time complexities.
MapReduce Architecture Components
Following are the essential components of MapReduce Architecture:
1) Client: The client is the source of Jobs or one who assigns Jobs to MapReduce for processing. A MapReduce architecture can consist of multiple clients that continuously send jobs to the Hadoop MapReduce Manager for processing.
2) Job: The Job is nothing but the actual work that the client wants to accomplish. A Job consists of many small tasks and the client wants to process them all.
3) Hadoop MapReduce Master: At this stage, MapReduce Master divides the main Job into subsequent job-parts.
4) Job Parts: The Job-parts are nothing but the small tasks produced after dividing the main job and the result of all the job-parts are combined to produce the final output.
5) Input Data: This is the data provided to MapReduce for processing.
6) Output Data: This is the final data which will be obtained after processing.
Role of Job tracker and Task tracker in MapReduce: The entire MapReduce execution process is being controlled by two main entities which are:
a. Job Tracker
b. Task Tracker
Let us understand how these two entities deal with the MapReduce execution process.
Job Tracker- The Job tracker manages all the resources and jobs across a cluster. A job is divided into multiple tasks and these tasks are run on multiple data nodes in a cluster. The Job tracker takes the responsibility to schedule and run tasks on different data nodes.
Task Tracker- The Task tracker works based on the instructions of the Job tracker. It is deployed on all the nodes available in the cluster in order to execute the MapReduce tasks based on the Job Tracker instructions.
Conclusion: MapReduce is a technological breakthrough in the world of big data. It has got huge popularity because of its capability to process unstructured data on a large scale and the ability to process data parallelly. Hope this blog has helped you in finding some useful information about MapReduce Architecture and how data is processed using the MapReduce framework.
Happy learning!! Check out our Big Data Hadoop & Spark training by TrainingHub.io. This course has been designed to make the aspirants professional in HDFS, MapReduce, Yarn, HBase, Hive, Pig, Flume, Oozie, Sqoop, etc. Happy learning!
Suggested blogs
Recent blogs

21 February 2025
|
06 February 2025
|