Hadoop Architecture - What all you need to know: Apache Hadoop is a technological breakthrough in the world of big data processing. It is an open-source framework deployed to store and process huge volumes of data. Instead of using a single computer to store and process data, Hadoop supports clustering of groups of computers to conduct quick analysis on massive datasets. In this blog, we are going to gain in-depth knowledge of Hadoop architecture and various concepts associated with it.
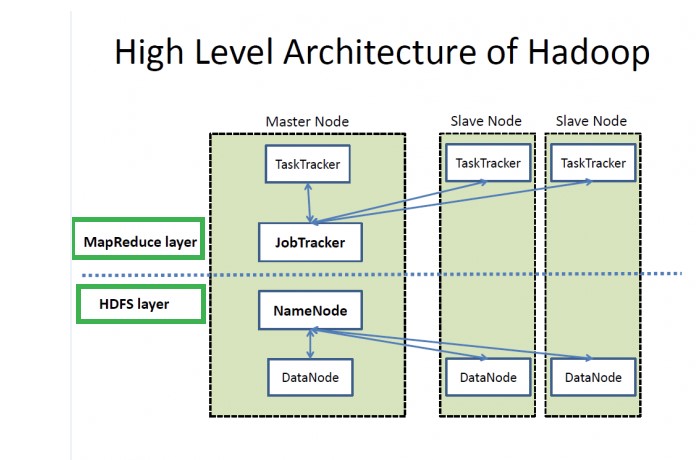
Hadoop Architecture Overview: Apache Hadoop is a highly flexible, reliable and easy to scale framework that supports a wide range of hardware and software platforms. Hadoop follows a master-slave architecture design for distributed data processing and data storage. Master nodes are responsible to manage resources and assign tasks to slave nodes. The Slave nodes perform the actual computing and store the real-data. Following are the 3 major components of Hadoop Architecture:
1. Hadoop Distributed File System (HDFS)
2. Hadoop MapReduce
3. Yet Another Resource Negotiator (YARN)

Explore the extensive Big Data Hadoop & Spark training offered at TrainingHub.io.
Let's discuss each component in detail:
1) HDFS: HDFS stands for Hadoop Distributed File System and it is one of the major components of Hadoop architecture. Features like high fault tolerance and flexibility to run on commodity hardware have set it apart from the other distributed file systems. HDFS acts as a storage place for large volumes of data and provides simple access to the data. It divides the data into small parts called blocks and stores them in a distributed manner. Hadoop File System was developed using a distributed file system design. Unlike other distributed systems, HDFS is highly fault-tolerant and can be used on commodity hardware. HDFS follows a master-slave approach and consists of the following elements:
a. Namenode
b. Datanode
c. Block
d. Replication Management
e. Rack Awareness Let's discuss each concept in detail.
a) Namenode: It is commodity hardware which contains the NameNode software and GNU/Linux operating system. This software is highly flexible and can be used on commodity hardware. The Name Node also acts as the master server and executes the following tasks:
> Manages the files system storage.
> Perform various file system operations which include closing, renaming, and opening files and directories etc.
> Monitors and regulates clients access to files.
b) Datanode: It is commodity hardware that contains the Datanode software and GNU/Linux operating system. Each node in the cluster consists of a data node and these nodes are responsible for managing the storage of their systems. Following are the operations performed by DataNode:
> DataNodes executes the read-write operations on the filesystem based on the requirements of the clients.
> They also perform the tasks assigned by NameNode which include creation, deletion, and replication.
c) Block: In general, the user data is stored in the HDFS files. In the distributed file system each file is divided into one or more segments and stored on individual data nodes. Each file segment is considered as a block. The default size of a block is 128 MB, and the size can be modified as per the requirement by making appropriate changes in the HDFS configuration.
d) Replication Management: Replication plays an important role in improving the availability of data in all types of distributed systems. To enhance the fault tolerance HDFS uses a replication technique. Using this replication technique it makes multiple copies of the blocks and stores them on different nodes. The number of copies is decided by the replication factor. The default replication copies are 3 but we can configure the value based on the requirement. In order to maintain the replication factor in a balanced way, Namenode gathers the block report from each DataNode. Sometimes there may be chances where there is a block over-replication or under-replication, at such times the NameNode adds or eliminates replicas accordingly.
e) Rack Awareness: The Rack in HDFS is defined as a physical collection of nodes in a Hadoop cluster. In general, we can have many racks in the production and each rack contains multiple DataNodes. To place the replicas in a distributed manner HDFS uses a rack awareness algorithm. The Rack Awareness algorithm provides high fault tolerance and low latency.

In order to achieve the rack information, NameNode maintains rack ids of each data node. The method of selecting the nearest DataNode based on the rack information is called Rack Awareness.
2) MapReduce: MapReduce is the software framework using which one can simply write applications to process huge volumes of data. It runs these applications parallelly on a cluster of commodity hardware in a fault-tolerant and reliable manner. The MapReduce algorithm consists of two essential tasks which are Map and Reduce. MapReduce job is associated with a number of Map and Reduce tasks. Each task works on a specific part of data and this procedure distributes the load across the cluster. The Map function performs tasks such as load, parse, transform and filter data. The output of the Map function becomes the input for the reduced tasks. Reduce tasks take the intermediate data from the map tasks and apply grouping and aggregation.
The Hadoop Distributed File System holds the input file of the MapReduce Job. The process to split the input file into input splits is decided by InputFormat. The Map task loads the input-split and runs on the node where the relevant data exists. MapReduce is divided into two major components which are Map and Reduce. Let's discuss each concept in detail and phases involved in them.
Map Task - Following are the various phases available in Map task:
a) RecordReader: The MapReduce RecordReader converts the byte-oriented view of input into record-oriented view for mapper and reducer tasks for processing. It takes the responsibility to process record boundaries and presents the tasks with values and keys.
b) Map: In this phase, the user-defined function called mapper processes the key-value pair from the RecordReader. During this phase, the mapper function produces zero or multiple key-value pairs. The Mapper function consists of 5 core components which are Input, Input Splits, Map, Intermediate output disk, and Record Reader. The Key-value pair is decided by the mapper function. In general, the key is nothing but the data on which the reducer function performs grouping operation. The value is considered as the data which gets aggregated to produce the final result in the reducer function.
c) Combiner: A Combiner is also called a semi-reducer and it is an optional class. It receives the input from the Map class and transfers the output key-value to the Reducer class. The core function of the combiner is to aggregate the map output records with the same key. The Reducer task receives the output of the combiner as input over the network. The combiner function helps in compressing the large volumes of data to move over the network.
d) Partitioner: The Partitioner takes the intermediate key-value pairs from the mapper function and then splits them into shards. It makes partitions based on the user-defined function and works similar to a hash function. The number of partitions is always equal to the total number of Reducer tasks for a job. For a job, the total number of partitions is always equal to the total number of Reducer tasks. From each map task, the partitioned data is written in the local file system.
Reduce Task - Following are the various phases available in reduce task:
a) Shuffle and Sort: The reducer task begins with the shuffle and sort phase. In this phase, the data written by partition will be downloaded into the machine where the reducer is running. This shuffle and sort step collect all the individual data pieces and make it as a large data set. The core task of the sort function is to gather all equivalent keys together. And this process makes the iteration far simple in the reduce task. The framework automatically handles everything and there is no chance for making customizations to this phase. The developer uses a comparator object to control the process of how keys get sorted and grouped.
b) Reduce: In this phase, the reducer task aggregates the key-value pairs. The framework passes the function key along with the iterator object which contains all the values related to that key. We can filter, aggregate and combine data in different ways by writing a reducer function. Once the execution process of the reduce function is over it gives zero or more key-value pairs to the output format. The reduce function works similar to map function and changes from job to job.
c) OutputFormat: This is the final step of MapReduce and it receives the key-value pair from the reducer phase & writes the same to the file using a record writer. Here the key and value are separated by default by a tab and the records are separated by a newline character. Here we have an option to make desired customizations and give a rich look to the OutputFormat. At the end of this phase, the final data gets written to the Hadoop Distributed File System.
3) YARN: YARN stands for Yet Another Resource Negotiator and it is one of the core components of Hadoop architecture. YARN helps Hadoop to run and process data for stream processing, batch processing, graph processing and interactive processing which are stored in HDFS. This is how YARN helps in processing various types of distributed applications other than MapReduce. The Core idea of YARN is to divide the resource management and job scheduling/monitoring into different daemons. YARN allocates the system's resources to the different applications running in a Hadoop cluster and also schedules tasks that need to be executed on different cluster nodes. In YARN we have a global resource manager and per-application ApplicationMaster. The YARN framework consists of two daemons which are NodeManager and ResourceManager. The ReosurceManager takes the responsibility to allocate the resources to the different running applications in the system. The NodeManager job is to monitor resource usage and report it to the ResourceManager. The resources include memory, CPU, disk, network, etc.
The Resource Manager consists of two important components which are:
a. Scheduler
b. Application Manager
a) Scheduler: The Scheduler allocates resources to various running applications based on the requirements. It only performs resource allocation tasks but does not look after or track the status of the application. It does not reschedule the tasks by taking software and hardware failovers into consideration.
b) Application Manager: The application manager takes responsibility for managing a set of submitted applications or tasks. It conducts a detailed verification on submitted application’s specifications and may reject them if the applications do not have enough resources. It also eliminates the applications that are already submitted with the same ID. The next step is that it transfers the verified application to the scheduler. The application finally analyzes the position of applications and manages finished applications to free up Resource Manager memory. It also saves the cache of finished applications and removes the old with an aim to allow this space to newly submitted applications.
Features of YARN - Following are the features which made the YARN popular:
a) Multi-tenancy: YARN allows access to a wide range of data processing engines which include stream processing engine, batch processing engine, graph processing engine, interactive processing engine and much more.
b) Cluster Utilization: All the clusters are used in an optimized way because YARN helps Hadoop to use the clusters dynamically.
c) Compatibility: YARN is highly compatible and it can also be used with the Hadoop first version which is Hadoop 1.0.
d) Scalability: YARN is capable of scaling to thousands of nodes. The scalability of YARN is based on the ResourceManger and is proportional to the number of active applications, nodes, frequency of heartbeat and active containers.
Hadoop Architecture Design – Best Practices to Follow:
Following are the simple rules to keep in mind while designing the Hadoop architecture:.
> Use best quality commodity servers to make it cost-effective and easy to scale out of complicated business use cases. The ideal configuration for Hadoop architecture is to start with 96 GB of memory, 6 core processors, and 104 TB of local hard drives. This is just a considerable configuration but not an absolute one.
> To gain efficient and faster processing of data, move the data close to the processing instead of dividing them into two.
> Hadoop gives you high performance and scales easily with local drives so it is advisable to use Just a Bunch of Disks (JBOD) with replication instead of using redundant array of independent disks (RAID).
> Plan the Hadoop architecture for meeting the multi-tenancy criteria by sharing the capacity scheduler with compute capacity and HDFS storage.
> Do not make any modifications to metadata files, as it can destroy the state of the Hadoop cluster.
Conclusion: With this, we have come to the end of this Hadoop architecture blog. In this blog, we have covered all the important aspects of HDFS, YARN & MapReduce. Hadoop's redundant storage structure makes it robust and fault-tolerant. The MapReduce framework works on the data locality and moves computation close to the data. Following best practises in designing the Hadoop's architecture would help in eliminating future issues. The design of Hadoop architecture makes it more scalable, efficient, and economical in the world of big data processing.
Happy learning! Explore the TrainingHub.io's Big Data Hadoop & Spark training program today!
Suggested blogs
Recent blogs

21 February 2025
|
06 February 2025
|