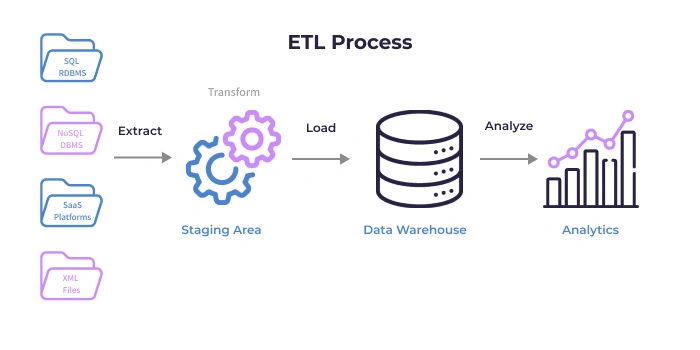
Organizations across the globe are largely relying on big data to gain valuable insights and to outgrow in this competitive world. It is a challenging task to process the ever-increasing volumes of data using traditional systems. To process these huge volumes of data and to gain valuable insights out of it, the data needs to go through three different tools which are ETL tools, data warehouse tools, and BI tools.
ETL stands for Extract, Transform and load. Extract connects to a data source and gets the data. Transform functionality turns data into a usable format by making appropriate changes to it. Load functionality moves the data into a targeted data warehouse platform.
There are a series of steps to be followed for the successful implementation of an ETL development for a data warehouse project. It is associated with multiple tasks that are needed to be completed before its launching. There are proven steps to be followed while performing extraction, transformation and loading data into a data warehouse platform. These steps are considered as best practices for ETL development.
ETL Best Practices:
1) STEP 1 - UNDERSTAND THE DATA REQUIREMENTS:
A data warehouse platform acts as a base for performing any analytics on business data. By keeping this in mind there is a need to define the number and type of visualizations required should be defined in this phase. Data warehouse architects and business analysts are the ones who determine data needs and data sources. Once this process gets finished the ETL developers can start to implement the process.
2) STEP 2 - DATA CLEANING AND MASTER DATA MANAGEMENT:
Here we have to ask a series of questions like a source of data? Is it approved by the governance group? Does this data fulfil the norms of master data management (MDM)? Is it from the right source? Without MDM and governance, data cleansing becomes a challenging task in the development of ETL.
3) STEP 3 - MAPPING DATA SOURCE TO WAREHOUSE:
Businesses can have a wide range of data sources. The sources may range from machine-generated data to text files to direct database connection. There is also a need to consider various security permissions and data types. The mapping should be managed in a similar fashion to the source code changes tracking process.
4) STEP 4 - HAVE A CLEAR IDEA OF DEPENDENCIES:
It is a common task to load data parallelly whenever possible and required. A typical medium-sized data warehouse is loaded with gigabytes of data every single day. The data model has some dependencies associated with loading data into a data warehouse. There are some ETL jobs or packages for specific data that need to be loaded completely before starting loading other jobs or packages.
5) STEP 5 - CRITICAL EVALUATION:
It is very vital to have a critical assessment on the areas like expected data growth rates, the time it takes to load constantly growing volumes of data. If you specify a window time to run the ETL process, make sure that all the process should be completed within the timeframe. Also, it is an important element to consider the availability of archiving of incoming files from source systems and outside parties.
6) STEP 6 - LOGGING MECHANISMS:
It is very essential to track the count of incoming rows and the output rows to a staging database or landing zone. It helps in ensuring the expected data gets loaded into the targeted system. Each ETL tool comes with its own logging mechanism. When it comes to Enterprise scheduling systems they come with a separate set of tables for logging. Each serves for a specific login function and it's not possible to override one another in the majority of environments.
7) STEP 7 - SCHEDULING:
You can schedule an ETL on a daily, weekly or monthly basis based on your requirement and also analyze the history of an ETL for a set of data sources. Scheduling is often taken care of by outside groups rather than ETL development teams. It is very essential to know the volumes of data, and dependencies to ensure that the infrastructure is able to perform all the tasks effectively.
8) STEP 8 - ALERTS:
In general, an alert system is meant to send process completion notification to the technical managers. But this may become noise as each time it completes a process it gives a notification. Instead of this, it would be far better to configure a notification system that notifies when anything goes wrong.
9) STEP 9 - RESTARTABILITY:
There may be chances to go something wrong in the middle of the execution of an ETL process.
An ETL functionality is involved with hundreds of data sources and there should be a way to find the state of the ETL process at the time of failover. The aforementioned logging helps in determining the point where the flow stopped. It is also crucial to define whether the data should be rolled back or started manually in the case of failover.
10) STEP 10 - DOCUMENTATION:
All the important elements should be documented for future references. Things like an inventory of jobs and non-functional requirements need to be documented as text documents, workflows, and spreadsheets.
Conclusion:
Each business is unique and requires specific solutions for various requirements. Having a clear understanding of any organizational needs plays a crucial role in the successful implementation of any project and the same is the case with the ETL implementation. The above stated are the typical steps involved in developing an effective ETL for a data warehouse platform.
Happy reading! Elevate your career in data warehousing with our Microsoft Data Warehousing Training.
Suggested blogs
Recent blogs

21 February 2025
|
06 February 2025
|