ETL & Data Warehousing: The Ultimate Guide for ETL Basics
02 November 2023
|
Data has been playing a key role in the success of modern businesses. Effective utilization of growing business data helps organizations in minimizing risks and maximizing profits by providing them with the right insights. In order to process these huge volumes of data, organizations have to deal with multiple data processing tools. In this blog, we are going to talk about what is data warehousing and how ETL tools play a crucial role in processing big data.
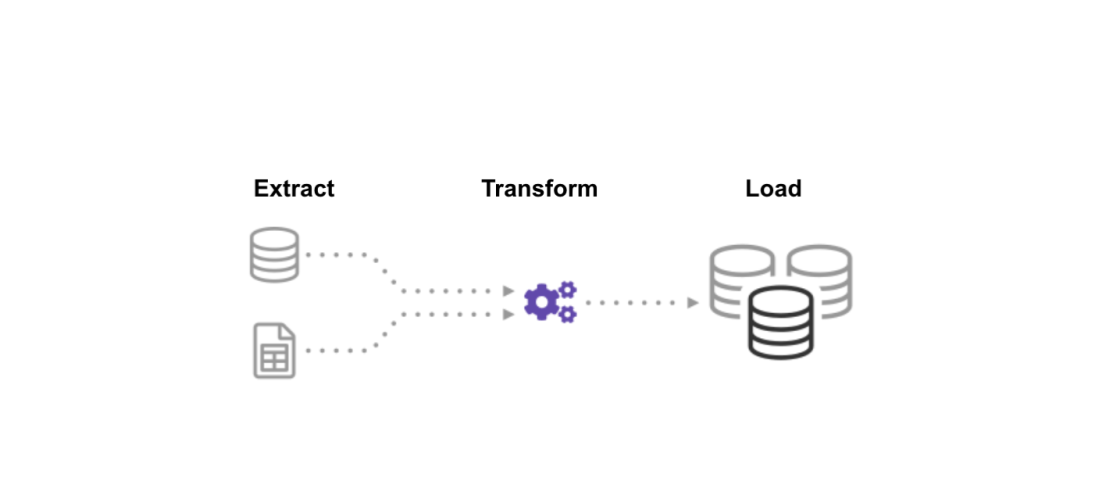
ETL tools and Data warehouse platforms go hand in hand to perform core data processing operations. In order to load any data into a data warehouse, one has to use ETL (Extract, Transform, Load). Whether you want to build a pipeline between applications or to load data from any of your data sources into a data warehouse you need an ETL tool.
The growth of big data has been multiplying every year and this data is showing a major impact on the success of any business. Global corporations believe that failing to embrace the advantages of big data would eventually result in falling behind the market competition. To leverage the benefits of big data organizations majorly uses three tools which include, data warehouse tools, ETL tools and BI tools.
In this blog let’s understand what ETL is, how it works and understand the basics of ETL tools.
Following are the concepts we are going to cover in this blog:
1) What is ETL?
2) Comparison between ETL and ELT
3) Technical concepts of ETL and ELT
4) Types of ETL tools
5) Advantages of ETL tools
6) Conclusion
1) What is ETL?
ETL is a short form of Extract, Load and Transform. It pushes huge volumes of raw data from multiple business sources to data warehouse tools by making the data ready for analysis. In simple terminology, an ETL tool extracts data from various business sources, makes some transformations to raw data in order to make it compatible with the destination system and loads data into the targeted system. The targeted systems may be data warehouses, databases, data lakes or maybe any application system.
Any ETL tool consists of three primary steps, let's discuss them one by one:
Stage 1) Extraction - This is the first step in the ETL architecture. Here large volumes of data extracted from a varied business source and moved to a staging area. The data that comes from diversified sources may be in a structured or unstructured format, loading this data directly into the data warehouse would result in failure or corrupted data. The staging area acts as a place where data is cleansed and organizes data and prevents corruption of data in a data warehouse.
The biggest challenge associated with the extraction process is how your selected ETL tool is going to handle structure and unstructured data sets. It becomes a challenging task to extract the unstructured data (e.g., emails, web pages, etc.) if the selected ETL tool is incapable. In such cases, you are required to create a custom solution for it.
Following are the three data extraction methods:
- Full Extraction
- Partial Extraction- with the update notification
- Partial Extraction- without update notification
Following are some of the validations done during extraction:
- Data type check
- Records reconcile with sourced data
- Ensuring no unwanted/spam data loaded
- Eliminate fragmented data
- Make sure all the keys are in the right place or not
Stage 2) Transformation - This stage is considered a critical phase in the ETL process. In this process, the data extracted is in the raw form and needs some alterations to use it. Hence it is required to be cleansed, mapped and transformed. This process contributes a crucial part to develop meaningful insights using BI reports. In the transformation stage, you are required to apply a set of functions to extracted data. If in case extracted data requires no transformation then it is called a direct move or pass-through data.
Following are the various methods applied to yield the right data:
- Cleaning
- Filtering
- Sorting
- Joining
- Deduplication
- Splitting
- Summarization
Stage 3) Loading - Data loading into the targeted system is the last step in the ETL process. In general, the data needs to be loaded into a data warehouse in batches or all at once based on the organizational requirement and optimized for performance.
Recovery mechanisms should be configured to meet the load failures and to restart from the point without losing data integrity. Data warehouse admins need to manage loads based on the server performance.
Explore the world of data warehousing excellence with our Microsoft Data Warehousing Training, your gateway to advancing your career in this dynamic field.
2) Comparison between ETL and ELT
There are two different methods used for loading data from the source point to destination among that one is ETL (extract, transform and load) and the other is ELT (extract, load and transform). Some may choose to transform the data before it gets loaded into a data warehouse and others may load directly raw data into the targeted system before transformation is done to the data. In general, the ELT process is used with NoSQL databases and Hadoop clusters.
Both ETL and ELT come with their own set of advantages and disadvantages. As of now, many data warehouse platforms are leveraging the benefits of using the ETL process to process data. The ELT process is best suitable and widely used when there are huge volumes of data that needs to be processed. As ELT doesn’t have any staging area it gives poor data for running queries.
The major advantage of using ELT is the rapid data ingestion speed. It is because the data is directly dumped into the warehouse before it is even cleansed. The ELT process is recommended to use where the huge volumes of data required to dump irrespective of considering the value of data.
Let’s Understand the scenarios in using ETL and ELT using OLAP
ETL and OLAP Data Warehouses
ETL has been the first choice for many data engineers to integrate with diversifying data resources to online analytical processing (OLAP) data warehouses. It is just because the ETL makes data analysis far simpler.
In general, business applications use online transactional processing (OLTP) databases. These databases allow the users to write, edit, and update information inside them and not meant for data analysis. Here organizations use OLAP to gain high-speed data reading and analysis. That’s the main reason behind using ETL to transform the OLTP information so the data becomes ready to work with OLAP data warehouses.
ETL Process:
- Data extracted from multiple sources
- Applied required transformations within the staging area and made it ready to integrate with other data sources.
- Data transferred into online analytical processing (OLAP)
ELT and Data Lakes:
ELT works opposite to ETL and brings a lot of flexibility in terms of data transformation. Using ELT you can load data into a “data lake” and store all types of structured and unstructured data for future reference.
ELT and data lakes are best suitable for the modern cloud-based servers like Google BigQuery, Snowflake, and RedShift. These tools come with powerful capabilities to make required transformations on the required data. ELT performs transformations right before dumping the data into BI tools.
Following are some of the challenges associated while working with the ELT process:
- This technology requires more development
- Data Lake and ELT tools are still evolving stage
- ELT is not that effective compared to ETL
- Professionals who can build ELT pipelines are difficult to find
3) Technical Points to look after while designing your ETL or ELT pipeline
Following are the critical areas one should pay attention to while designing ETL and ELT processes.
Effective logging system: It is very essential to check whether your data systems provide effective login for the new information or not. To have a check over this you need to audit data once it is loaded to find lost or corrupted files before it enters the database. Having an effective auditing process would help you debug the ETL/ELT pipeline in case arising of any data integrity problems. Flexible enough to handle structure and unstructured data.
In the course of data analysis, your data warehouse requires you to align with multiple data sources such as Salesforce, PostgreSQL, in-house financial applications and much more. Sometimes the information you get from the sources may lack data structures needed for analysis. Your ETL/ELT process should be flexible enough to deal with all forms of structured and unstructured data.
Consistent and dependable: Sometimes there may be failover or crash, or overload of ETL/ELT Pipeline due to multiple reasons. In order to prepare for these unexpected events, you should have to build a fault-tolerant system that can go live right after any failover. It helps you in a continuous flow of process data even in case of any sudden failover.
Build a notification system: To have clear business insights, you require building an alert system that should be capable enough to notify the essential problems associated with the ETL/ELT process. For instance, the report system should be able to send notification in case of any connector errors, bugs, API expiry, database errors, etc.
Data Accessibility Speed: The data warehouse and BI tools are able to provide you right and accurate insights only when the data given to them is up to date and error-free. In order to get effective business insights, it is essential to minimize the time taken to move data from source to destination.
Easy Scalability: The ETL/ELT process should be flexible enough to scale up and scale down based on the ever-changing organizational requirements. It not only provides you with a flexible system but also helps you in minimizing the cost associated with cloud servers.
4) Types of ETL Tools
There are majorly two types of ETL tools which are cloud-based and Open source. The selection of ETL tools depends on a variety of things like data warehouse architecture, operational structure, data schemas, and ETL needs.
Cloud-Based ETL Tools: These are the widely deployed ETL tools as they come with some advanced capabilities required for easy integrations, real-time streaming, and easy process to build ETL pipeline. One of the core advantages of Cloud-based ETL tools is that they act swift enough to fulfil the data needs. It becomes best practice if you are using cloud-based data warehouse platforms such as Snowflake, Google BigQuery, or Redshift.
Open source ETL tools: There is a wide range of open-source frameworks and libraries available; you can use them to build ETL Pipelines in Python. You can easily build and customize ETL tools to meet the unique needs of the organizations. But the major disadvantages of using open-source ETL tools demand lots of coding, requires more manual interaction and requires frequent changes when anything new is added.
5) Advantages of ETL tools
Following are the various advantages of using ETL tools: Easy to use: The biggest advantage that arises from using an ETL tool is the usage process. Once you select the data source the tool automatically identifies the data format and types of data. Moreover, it also defines the rules to extract, transform and load data into a data warehouse. This complete process is automated and eliminates the need to spend time writing lines of code.
Visual flow: ETL tools work based on GUI and offer a visual flow of the system’s logic. You can use the drag and drop function to display the data process.
Operational Resilience: Many data warehouse platforms often struggle during operation. ETL tools come with advanced built-in error handling features to help data engineers to develop effective and resilient ETL processes.
Handles complex data: ETL tools give great performance in moving large volumes of data. If the data is associated with complex rules, ETL tools simplify tasks and assist you with string manipulation, data analysis, and integration of multiple data sets.
Enhanced Business Intelligence: Data accessibility becomes easier than before because of ETL tools as it simplifies the process to access data by extracting, transforming and loading. Easy access to the right information at the right time helps in making data-driven decisions. Also allows the business leaders to retrieve the required information to make quick decisions.
6) Conclusion/Final Thoughts
ETL tools are playing a predominant role in the data processing segment. There are plenty of cloud-based and open source ETL tools available in the market. Each business is unique in nature and needs different ETL tools to fulfil its data processing needs. Hope this blog helped you with some useful insights.
Happy reading! Elevate your career in data warehousing with our Microsoft Data Warehousing Training.
Suggested blogs
Recent blogs

21 February 2025
|
06 February 2025
|